

In the last few weeks, every major AI platform has shipped managed agents.
They're responding to the same demand, for infrastructure to bring agents online, with the same kind of sandbox-based architecture. That architecture is wrong.
Managed agents don't belong in sandboxes. They belong in functions, with stateless agent logic, durability in the data layer and tool execution in backend systems.
That's the architecture — serverless agents — to wire agents into the workforce.
λ Serverless agents with Electric
Build and run serverless agents with Electric Agents now. See the Walkthrough guide.
Managed agents
In the last few weeks, what seems like every major AI platform has shipped their version of managed agents:
- Anthropic Managed Agents (April 8th)
- Cloudflare Project Think (April 15th)
- OpenAI Workspace Agents (April 15th)
- Azure Foundry Hosted Agents (April 22nd)
- Amazon Managed Agents (April 28th)
- LangChain Managed Deep Agents (May 13th)
- Google Agent Executor (May 20th)
These companies have the best visibility in the sector. They're seeing that the world needs managed agents.
As Sunil and Kate from the Cloudflare Agents team put it:
"The first wave was chatbots. The second was coding agents. We are now entering the third wave: durable, distributed agents."
This third wave is the wave of workforce transformation. Agents joining the workforce, one automation and one assistive task at a time.
Bringing agents online
For this to happen, agents need to be brought online, scaled out and integrated into the day-to-day systems and processes that companies run on.
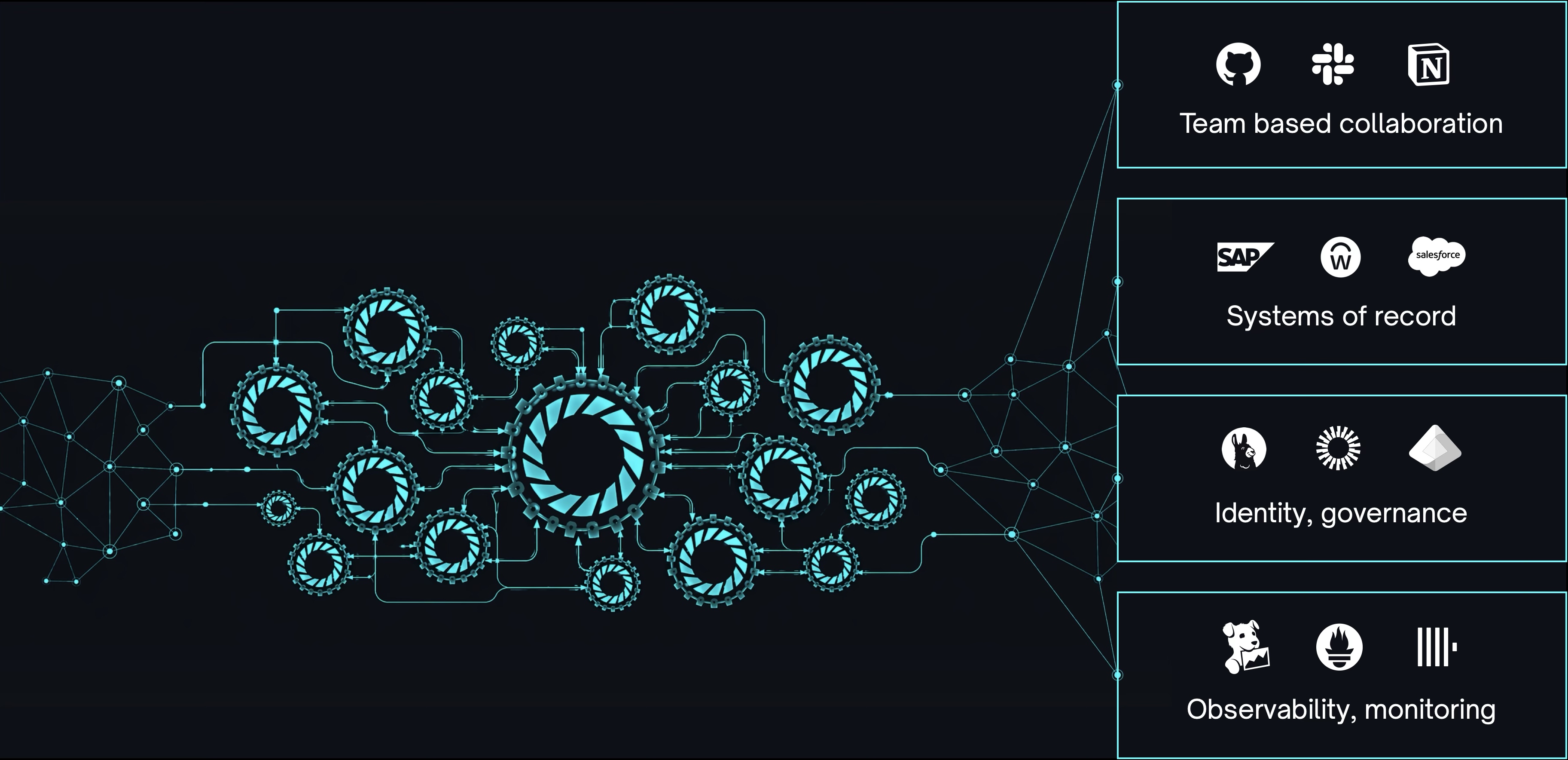
They need to be part of the team. Which means being wired into the tools that teams use to collaborate and get stuff done. They need to be tracked and managed, wiring them into governance processes and systems of record.
The rise of the sandbox
So how do you do that? Well, what is an agent? It's an LLM in a loop.
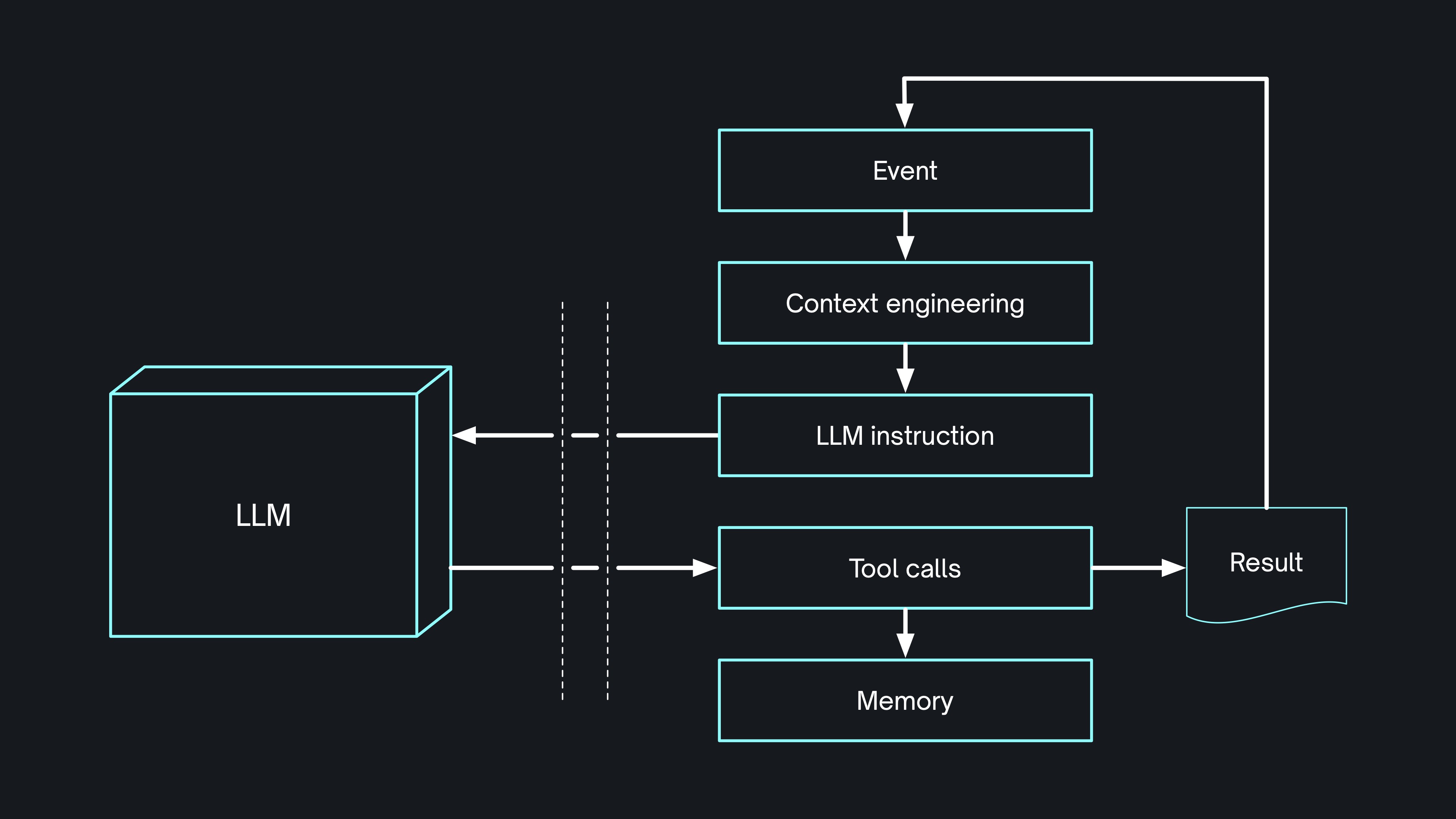
What everyone from Chris McCord onwards figured out is that the LLM is really good at using tools like bash and grep. So the harnesses running the agent loop were designed around these tool calls. Which means they need to run in an environment that supports them, aka a computer.
Then, initially, when the LLM wanted to run a command, we reviewed it and manually approved (or rejected) the execution. However, as the agents got better, approving every command became boring and we designed ourselves out of the loop.
Hence the rise of the sandbox: an isolated computer in the cloud where a harness can loop away like crazy, getting stuff done without bothering you.
Sandboxes for managed agents
This led to an explosion in sandbox infrastructure. With some awesome companies like Daytona becoming the fastest growing infra in history. So, it's no surprise that the new infrastructure for managed agents has been based around sandboxes.
For example, here's Satya Nadella, the Microsoft CEO, on the Azure Foundry launch:
Every agent will need its own computer. And with new Hosted agents in Foundry, every agent gets its own dedicated enterprise-grade sandbox
Which sounds very plausible. Until you consider the consequences of sandbox isolation for managed agents.
Limitations of sandboxes
There are three main downsides of sandbox isolation and all of them have serious consequences for managed agents:
- resource efficiency — which becomes more important the more agents you run
- fragmentation — which is directly opposed to wiring into the business
- coordination — which is critical for online agents
1. Resource efficiency
Running an agent inside its own VM or Docker container, or even a Firecracker, uses more compute resource than is needed to run the agent logic.
| Isolate | Start time | Memory overhead |
|---|---|---|
| Traditional VM | seconds | 256MB+ |
| Docker Container | ~500ms | 50MB |
| Firecracker microVM | ~125ms | 128MB |
| V8 isolate worker | <5 ms cold; sub-ms warm | 2MB |
Most agent operations, be they tool calls or LLM instruction, are I/O based. You send a request to a data system or the Anthropic API and wait for the response to be streamed back. There's really no need to hold a whole computer in memory just to make an API request.
This tends not to matter when you're running at smaller scale. The value of the agent system and the cost of LLM inference outweigh the cost of standard compute. However, it does matter when you have lots of agents.
If your business is running on agents, and those agents are spawning sub-agents every time there's a customer interaction, then sandboxes are a blunt instrument with a lot of wasted compute.
2. Fragmentation
Perhaps most fundamentally, sandboxes lead to fragmentation of artefacts and decision traces.
A harness looping away inside a computer uses operating system primitives like files and processes. If the power of the agent is that it can do what it likes on that computer, then it's going to generate a whole load of arbitrary activity and artefacts.
For example, if I run Claude Code on my local computer and ask it to spawn sub-agents to do some parallel research, it's going to:
- spawn those sub-agents in operating system processes
- store their session logs in
.jsonlfiles inside a hidden folder in my user directory - create and edit files in arbitrary locations
- make all sorts of arbitrary HTTP requests
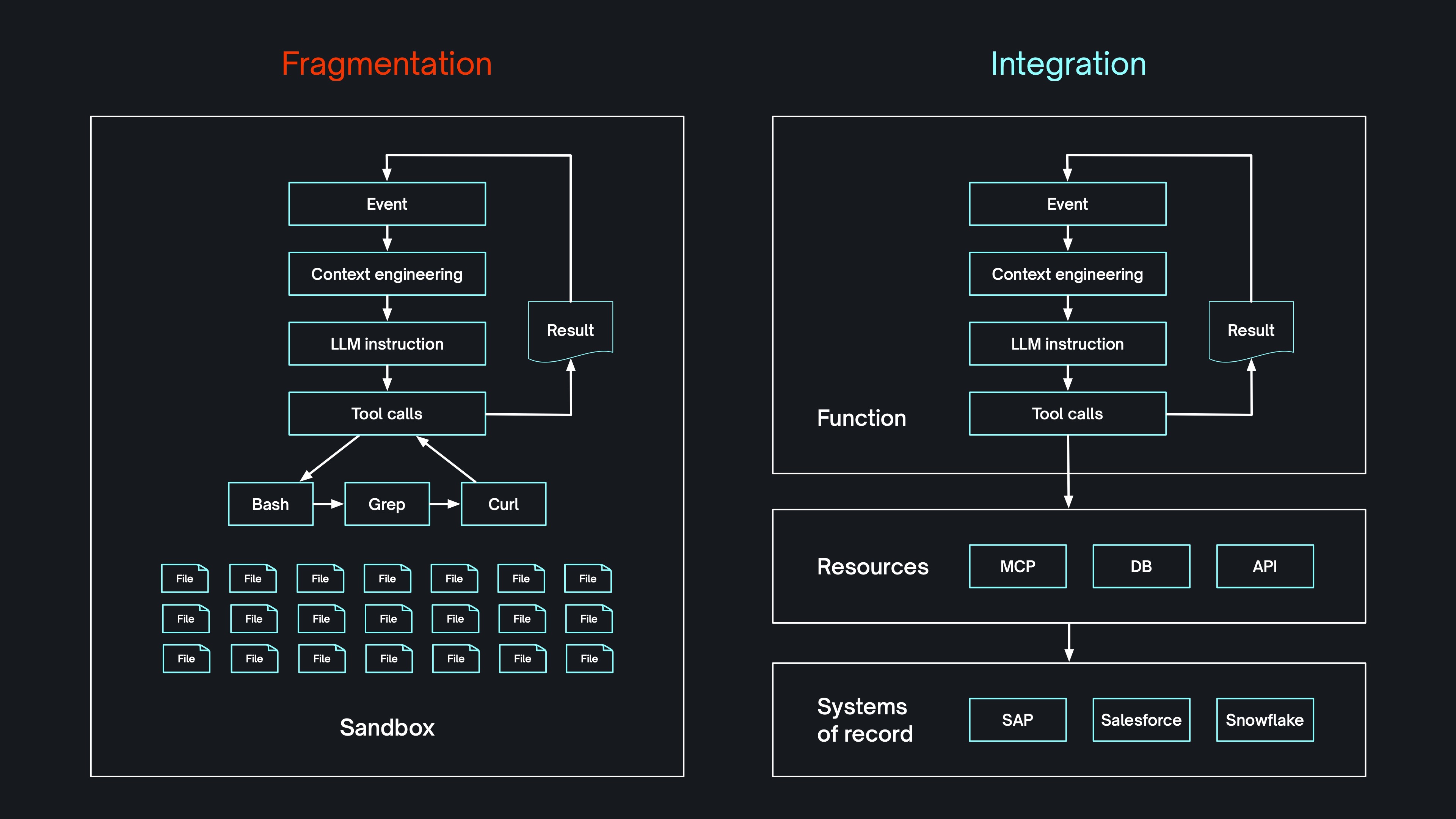
That's exactly what you don't want from agents you're running your business on. Because what happens when you want to manage, monitor, collaborate on or review the agent activity? What are you going to do, ssh into the sandbox?
No, you need to be able to track and trace the activity and artefacts and wire them into the business.
3. Coordination
Traditional software is deterministic and deployed with pre-defined topologies. Agents are not like that. Agents can spawn other agents, in increasingly dynamic and sophisticated topologies.
Coordination between managed agents has all the challenges of traditional distributed systems (durability, addressability, reactivity, spawning, signaling, scheduling, communication, coordination, concurrency, contention) but amplified by the scale, parallelism and dynamic nature of agents.
Sandboxes compound the problem by forcing you to pre-define the APIs and communication topologies between managed agents. Managing this kind of combinatorical complexity with manual data wiring hits a wall at agent scale.

Breaking out of the sandbox
The more sophisticated platforms are seeing these limitations and evolving to break out of the harness-in-a-sandbox model.
Pulling apart the harness
In their Scaling Managed Agents post, Anthropic explains their approach:
The solution we arrived at was to decouple what we thought of as the “brain” (Claude and its harness) from both the “hands” (sandboxes and tools that perform actions) and the “session” (the log of session events).
Google's Agent Executor (AX) platform explicitly separates the agent logic from the tool execution environment:
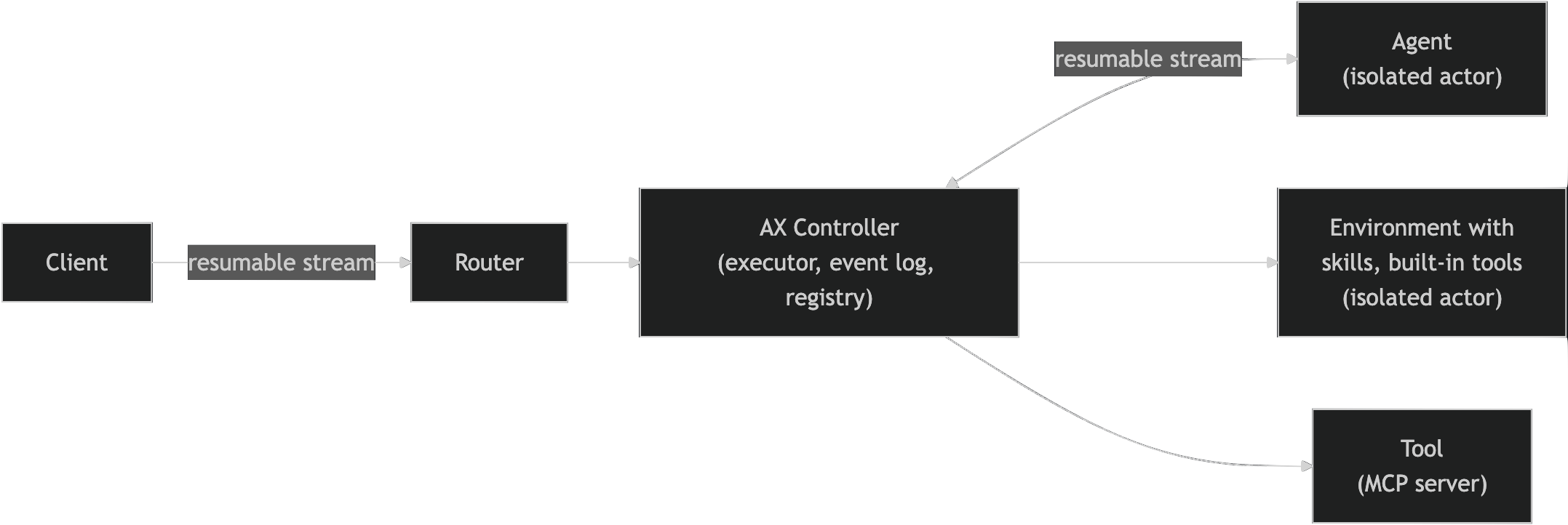
This separation of concerns and spectrum of execution environments allows us to rethink isolation.
Rethinking isolation
When an agent is a harness, designed to run on a local computer, everything needs to run in a full sandbox. However, when you've pulled apart the harness, you can see that agent logic and tool execution require different levels of isolation.
For example, Cloudflare have a spectrum of compute environments, the execution ladder, ranging from dynamic workers to full sandboxes. Agent logic can run in a lightweight V8 isolate, like a function, whilst heavier tool calls can be executed either in sandboxes, or in external backend systems.
This genuinely changes the game for managed agents. Allowing the agent logic to run in serverless functions while the tool calls are executed in backend systems. This transforms the resource efficiency of managed agents, allowing them to scale to zero like edge functions. And it solves fragmentation because the tool calls are executed in managed systems that you control and can monitor.
Turning the agent inside out
One of the most influential talks in data systems is Martin Kleppmann's from Strange Loop in 2014 about Turning the database inside-out. His concept was that databases are built on logs. What if you turn them inside-out and put the log on the outside?
Well, as we know, agents are logs:
What happens if you turn the agent inside-out and put the session log on the outside?
The answer is that it solves the dynamic coordination challenge. Allowing agents, users and systems to connect-to and monitor other agents by subscribing to and interacting directly with the log — rather than going through a pre-defined interface.

Serverless agents
Pulling apart the harness, rethinking isolation and turning the agent inside-out leads to a new architecture of serverless agents.
One where you treat agents as logical entities, model agents as data, separate agent logic from tool execution, run the agent loop as a stateless function and execute tool calls through your backend systems.
Principles
The key principles of serverless agent architecture are:
- Treat agents as logical entities
Agents are logical entities that exist, even when they're not running. - Model agents as data, not compute
Agents live in the data layer. Durable state, not durable execution. - Separate agent logic from tool execution
Pull apart the harness to seperate the brains from the execution. - Run the agent loop as a stateless function
With durability in the data layer and the ability to scale to zero. - execute tool calls through backend systems
for isolation and so artefacts and decision traces can be captured
Benefits
The result is a better way to scale-out and integrate agents into the business:
- scale: workforce-scale agent deployment becomes more efficient and elastic
- integration: no fragmentation; thinking and artefacts can be wired into the business
- collaboration: teams can collaborate across and around agent sessions
- transformation: businesses can integrate agents into the workforce
Building with Electric
You can build and run serverless agents today using Electric Agents.
Electric is the first agent platform built on a sync engine. It models agents as long-lived logical entities. Durability is stored in the data layer. Turning the agent inside out with Durable Streams as a first-class data primitive for the agent loop.
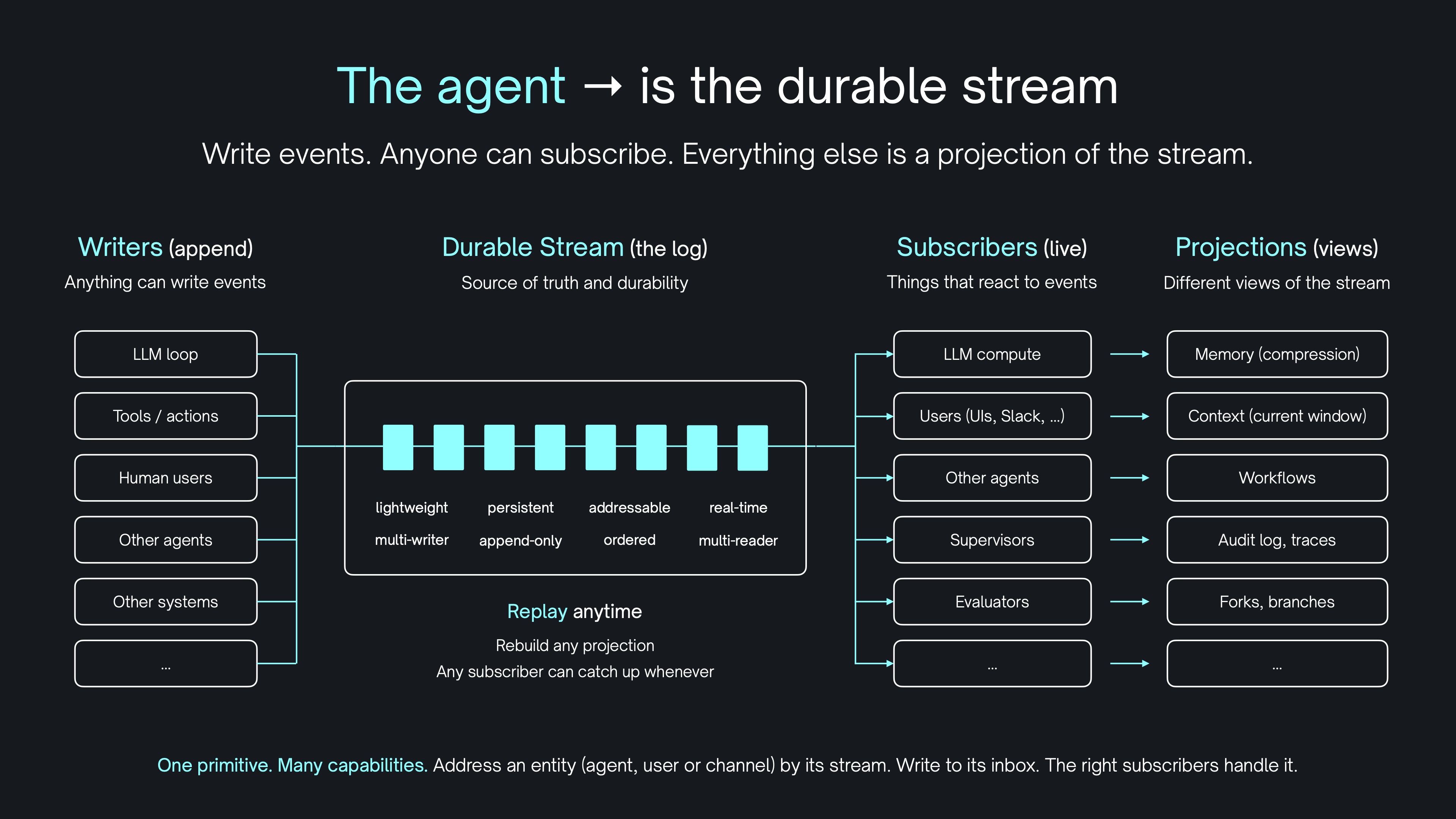
Agents are defined as serverless event handlers. The handler is a stateless function that can run as a request handler in your web application or edge workers. Tool execution is seperated from agent logic and designed to be handled by backend services.
For example, this is how you define an entity:
import { defineEntity } from "@electric-ax/agents-runtime"
defineEntity("assistant", {
async handler(ctx) {
ctx.useAgent({
systemPrompt: "You are a helpful assistant.",
model: "claude-sonnet-4-5",
tools: [...ctx.electricTools],
})
await ctx.agent.run()
},
})Everything in the handler function is your agent logic and the Electric Agents runtime takes care of the data wiring and scheduling for you. This allows you to run agents in functions, as long-lived logical entities that can scale to zero.
With Electric, agents are your code in your app, running on your compute with your AI engineering and models of choice. It's the infrastructure for managed agents, without the platform lock-in.
See the Walkthrough guide and video below to go from your first entity definition to collaborative, serverless, multi-agent systems on Electric:
Next steps
Managed agents don't belong in sandboxes. They belong in functions, with stateless agent logic, durability in the data layer and tool execution in backend systems.
You can build serverless agents today, on Electric Agents. Re-using your existing prompts, tool calls, AI engineering. As part of your existing web infrastructure.
See the blog post and dive into the Quickstart and Walkthrough guides now.
If there's anything you'd like to discuss, you're welcome to join the Electric Discord, say hello and ask any questions there.